機械学習とは? 仕組みやディープラーニングとの違い、活用例を解説
2026年02月26日

機械学習(Machine Learning)とは、データからパターンやルールを学習し、予測や判断を自動化する技術です。近年では、精度の高い需要予測や顧客行動の先読み、不正検知の自動化などに活用され、単なる技術トレンドにとどまらず、ビジネスの競争力を左右する重要な要素となっています。
本記事では、機械学習の基本概念をはじめ、AIやディープラーニングとの違い、業務での具体的な活用事例、ビジネスで活用する際のポイントまで分かりやすく解説します。
機械学習時のリスクは?AIガバナンス策定ノウハウBOOK
昨今、生成AIの活用が一般的になりつつある一方、AIによるリスクについても指摘がされています。
パーソルでは、AIガバナンスの必要性や策定までの流れ、策定時に押さえておくべきポイントを分かりやすく整理しています。
気づかぬうちに法制違反やプライバシーの侵害を起こさないためにも、AIガバナンス策定の際やリスクの洗い出しなどに、ぜひお役立てください。
目次
機械学習とは
機械学習とは、データをもとにコンピュータがパターンや規則性を学習し、予測や判断を自動化する技術です。あらかじめ人がすべての処理ルールを定義するのではなく、過去のデータから傾向を見つけ出し、その結果をもとに精度を高めていく点が特徴です。
従来のプログラムでは、「この条件ならこの処理を行う」といったルールを人が一つひとつ設計する必要がありました。一方、機械学習では、データを与えることでコンピュータ自身がルールを学習するため、複雑な判断や変化への対応が求められる業務にも活用できます。
そのため、機械学習は、需要予測や不正検知、顧客行動の分析など、大量のデータを扱い、精度の高い判断が求められる領域で特に力を発揮します。
機械学習とAI・ディープラーニングとの関係
機械学習を理解するうえで押さえておきたいのが、AI(人工知能)やディープラーニングとの関係性です。これらは互いに独立した技術ではなく、下図のような入れ子構造(親子関係)になっています。
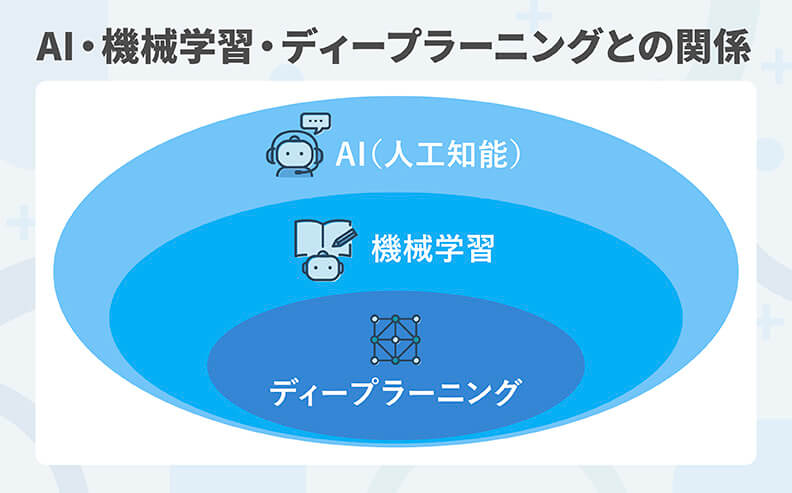
- AI(人工知能):コンピュータに人間のような知的なふるまいをさせる技術の総称
- 機械学習:AIを実現するための中核技術の一つで、データから学習し予測や分類を行う
- ディープラーニング:機械学習の一手法で、人間の脳を模したモデル(ニューラルネットワーク)を多層に重ね、より複雑なデータ処理を可能にしたもの
まずは、機械学習は「AIを構成する技術の一つであり、データから学習して判断や予測を行う仕組み」であるという位置づけを理解しておくことが重要です。ディープラーニングとの具体的な違いについては、後の章で詳しく解説します。
機械学習の仕組み:従来型プログラムとの違い
従来のプログラムでは、開発者があらかじめすべてのルールを明示的に定義する必要がありました。一方、機械学習では膨大なデータを活用し、アルゴリズムが自動的にパターンを見つけ出します。
機械学習の仕組みを理解する上で重要なのが「モデル」と「アルゴリズム」という2つの要素です。モデルとは、データから学習した結果を表すもので、予測や判断を行う際に使用されます。一方、アルゴリズムは、モデルを構築するための計算手法や学習方法を指します。これらが連携することで、機械学習は高い精度を実現します。
機械学習の主な3つの種類
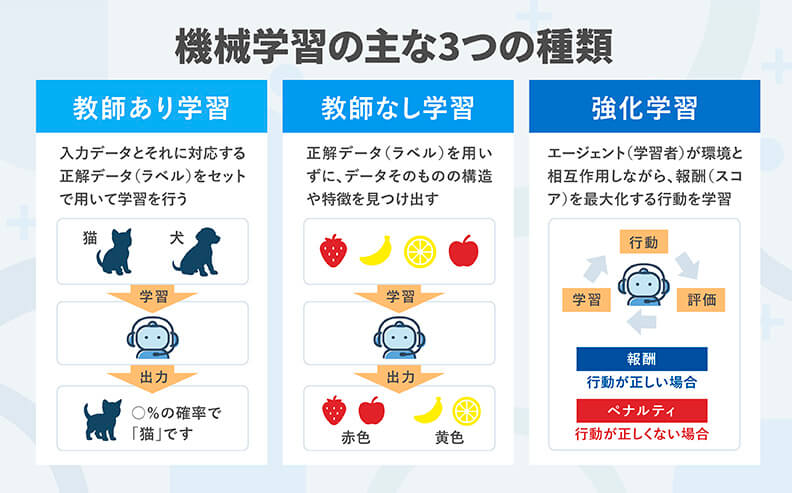
機械学習にはいくつかの種類があり、目的やデータの性質に応じて適切な手法を選択することが重要です。代表的な学習手法として「教師あり学習」「教師なし学習」「強化学習」の3つが挙げられます。これらはそれぞれ異なるアプローチでデータを学習し、さまざまな分野で活用されています。
教師あり学習
教師あり学習は、入力データとそれに対応する正解データ(ラベル)をセットで用いて学習を行う方法で、機械学習の中でも最も一般的に利用されています。アルゴリズムは、与えられたデータから規則性を学び、新しいデータに対しても予測や分類を行えるモデルを構築します。
例えば、電子メールのスパムフィルターでは、スパムメールかどうかを判定するために、過去のメールデータに「スパム」「非スパム」といったラベルを付けて学習させることで、新しく届いたメールがスパムかどうかを自動で判定できるようになります。
教師あり学習の強みは、ラベル付きデータが十分にある場合に高い精度を実現しやすい点です。一方で、ラベル付きデータを準備するには多くの時間とコストが必要になるという課題もあります。そのため、教師あり学習は、過去データが豊富に蓄積されている分野に適しています。
また、教師あり学習には「回帰」と「分類」という2つのタスクがあります。回帰は数値の予測を行うもので、需要予測や売上予測などが該当します。分類はデータをカテゴリーに分けるもので、スパム判定や画像認識などに活用されています。
教師なし学習
教師なし学習は、正解データ(ラベル)を用いずに、データそのものの構造や特徴を見つけ出す学習方法です。アルゴリズムは、データの類似性や分布をもとに、パターンを自動的に抽出します。
例えば、マーケティング分野では、顧客の購買履歴や行動データを分析し、似た特徴を持つ顧客同士をグループ化(セグメンテーション)する際に活用されます。これにより、顧客ごとに最適なマーケティング施策を検討しやすくなります。
教師なし学習の最大のメリットは、ラベル付きデータを用意する必要がない点です。一方で正解が存在しないため、結果の妥当性を判断するには、分析者の専門的な知識や経験が求められる場合があります。
教師なし学習の代表的な手法としては、データをグループ分けする「クラスタリング」や、データの特徴量を簡略化する「次元削減」などがあり、データ分析の初期段階で広く利用されています。
強化学習
強化学習は、エージェント(学習者)が環境と相互作用しながら、報酬(スコア)を最大化する行動を学習する手法です。正解データを与えるのではなく、行動の結果に応じて報酬やペナルティを与える点が特徴です。
例えば、チェスや将棋のAIでは、AIはゲームのルールに従いながら、勝利するための最適な戦略を学習します。勝利した場合には報酬が与えられ、敗北した場合にはペナルティが課されます。このプロセスを繰り返すことで、AIは勝つ確率を高める行動を学習していきます。
強化学習は、未知の環境や動的に変化する状況に適応できる点が強みです。一方で、問題設定やアルゴリズムによっては多数の試行(=時間)や大量の計算リソースを必要とする場合があります。また、報酬設計が適切でない場合、学習がうまく進まないこともあります。
そのため、強化学習は自動運転やロボット制御、ゲームAIなど、複雑な意思決定が求められる分野で活用が進んでいます。
機械学習の学習プロセス
機械学習を成功させるためには、データの準備からモデルの運用までを一連のプロセスとして捉えることが重要です。どれか一つの工程だけを最適化しても、期待した効果は得られません。ここでは、機械学習の代表的な学習プロセスを順を追って解説します。
データの収集と前処理
まず重要なのが、データの収集と前処理です。機械学習の性能は、入力データの質に大きく左右されると言われています。業務データやセンサーデータなどを収集し、欠損値の補完や異常値の除去、正規化といった前処理を行います。この工程を十分に行わないと、学習結果にノイズが混ざり、モデルの精度が大きく低下する可能性があります。
モデルの選択と構築
次に、目的やデータの特性に応じて、適切なモデルを選択し、構築します。例えば、数値を予測したいのか、分類を行いたいのかによって、選ぶアルゴリズムは異なります。この段階では、モデルを複雑にしすぎると学習データを過度に適合してしまう「過学習」が起こる可能性があります。そのため、精度と汎用性のバランスを考慮しながらモデルを設計することが重要です。
モデルの学習と評価
構築したモデルは、学習データを用いて訓練され、その後テストデータによって性能を評価します。評価には、精度や再現率、F値などの指標が用いられ、モデルがどの程度実用に耐えうるかを客観的に判断します。この工程を通じて、モデルの改善点を洗い出し、必要に応じて再学習やパラメータ調整を行います。
モデルの運用と改善
最後に、実際の環境でモデルを運用し、継続的に改善していきます。運用開始後は、データの変化や業務要件の変化によって、モデルの精度が低下することもあります。そのため、定期的な性能確認や再学習を行い、モデルを改善し続けることが重要です。
機械学習とディープラーニングとの違い
機械学習とディープラーニングは、どちらもAI活用において重要な技術ですが、ビジネスでの使われ方や導入時の考え方には違いがあります。ここでは、実務で技術選定を行う際に押さえておきたい視点から、両者の違いを整理します。
向いている課題の違い
機械学習は、需要予測や不正検知、顧客分析など、業務データをもとにした予測や分類、最適化に広く活用されています。数値データや構造化データを扱うケースが多く、ビジネス課題との親和性が高い点が特徴です。
一方、ディープラーニングは、画像認識や音声認識、自然言語処理など、人の認識に近い高度な処理が求められる領域で力を発揮します。非構造化データを扱う必要がある場合に、有力な選択肢となりえます。
導入・運用のしやすさ
機械学習は、モデルの構造や判断ロジックを比較的理解しやすく、PoC(検証)から本格導入、運用改善までを段階的に進めやすいという特徴があります。そのため、現場での改善や調整を繰り返しながら活用するケースにも向いています。
ディープラーニングは高い精度を実現できる一方で、モデルの中身がブラックボックス化しやすく、結果の説明やチューニングに専門知識が必要となる場合があります。導入後の運用体制も含めて検討することが重要です。
ビジネスでの選び方のポイント
どちらの技術が適しているかは、精度だけで決まるものではありません。自社の課題やデータの種類、運用体制を踏まえたうえで、以下のような観点から判断することが重要です。
- 業務データを活用した意思決定支援が目的か
- 高度な認識・理解が求められる課題か
- 導入後も継続的に改善・運用できる体制があるか
機械学習は比較的シンプルなアルゴリズムで幅広いタスクに対応できる一方、ディープラーニングは高度な処理能力を持ち、特に非構造化データの解析に優れています。用途や目的に応じて、これらの技術を使い分けることがAI活用を成功させるポイントです。
【関連記事】ディープラーニングとは? 意味や定義をわかりやすく解説
機械学習をビジネス活用するためのポイント
機械学習は、正しく活用すれば業務効率化や意思決定の高速化につながりますが、導入すれば自動的に成果が出るものではありません。これまで解説してきた内容を踏まえ、ビジネスで機械学習を活かすために特に重要なポイントを整理します。
目的と活用シーンを明確にする
機械学習の導入において重要なのは「何を解決したいのか」を明確にすることです。目的があいまいなままでは、モデル選定やデータ準備の方向性が定まらず、期待した成果につながりにくくなります。まずは業務課題を整理し、機械学習が本当に有効な手段かどうかを見極めることが重要です。
データと業務の前提を理解する
機械学習はデータをもとに学習するため、データの量や質、業務プロセスとの整合性が成果に大きく影響します。既存データで対応できるのか、新たなデータ収集が必要なのかを事前に確認し、現実的な導入計画を立てることが欠かせません。
導入後の運用までを見据える
機械学習は導入して終わりではありません。運用開始後も、データの変化や業務内容の変化に応じて、モデルの見直しや改善が必要になります。PoC(検証)だけでなく、継続的に運用・改善できる体制があるかどうかを考慮することが重要です。
機械学習の活用例
機械学習は、業界や業務を問わず、さまざまな場面で活用が進んでいます。ここでは、ビジネスや社会で活用されている代表的な事例をいくつか紹介します。
医療分野での診断支援
医療分野では、機械学習を活用した診断支援システムが、医師の診断を補助する役割を担っています。例えば、画像診断では、X線画像やMRI画像を機械学習モデルが解析し、異常の可能性がある箇所を検出します。これにより、診断の見落とし防止や早期発見につながり、医師の負担軽減と医療の質向上が期待されています。あくまで補助的な役割であるものの、現場での活用が進んでいる分野の一つです。
金融分野での不正検知システム
金融分野では、クレジットカードの不正利用検知や不正取引の管理に機械学習が活用されています。過去の取引データをもとに、通常とは異なる行動パターンを検知し、不正の可能性が高い取引をリアルタイムで抽出します。この仕組みにより、被害の拡大を防ぐと同時に、正当な取引への影響を最小限に抑えることが可能になります。
マーケティング領域における顧客行動予測
マーケティング分野では、顧客の購買履歴や行動データを分析し、次にとる行動を予測するために機械学習が活用されています。パーソナライズされた施策を実施しやすくなり、顧客満足度の向上や、売上増加につながります。データを活かしたマーケティングを実現するうえで、機械学習は重要な役割を果たしています。
製造・物流における需要予測と最適化
製造業や物流分野では、機械学習を用いた需要予測や業務最適化が進んでいます。過去の販売データや季節要因、市場動向などをもとに需要を予測することで、生産計画や在庫管理の精度を高めることができます。これにより、過剰在庫や欠品のリスクを抑えつつ、コスト削減や安定供給の両立が可能になります。

機械学習を導入しただけで終わらせないために
機械学習は、多くの分野で活用が進む一方で「検証までは進んだが、その先が続かない」「導入したものの、業務改善につながらなかった」といったケースも少なくありません。こうしたつまずきの多くは、技術そのものではなく、業務課題・データ・運用の整理が十分に行われていないことに起因しています。機械学習は、単体で導入すれば成果が出るものではなく、業務プロセスや導入後の運用まで含めて設計する必要があります。
そのため、自社だけでの検討が難しい場合には、AIの知見と業務理解の両方を持つ専門的な支援を活用するという選択肢も考えられます。パーソルグループではAIの構想策定からPoC、本格導入、そして内製化までを一気通貫で支援するコンサルティングサービスを提供しています。AI導入・活用にお悩みの際は、ぜひお気軽にご相談ください。
まとめ
機械学習は、データをもとに予測や判断を行うことで、業務効率化や意思決定の高度化を実現できる技術です。本記事では、機械学習の基本的な考え方から、仕組みや学習方法、ディープラーニングとの違い、活用例までを整理してきました。
一方で、機械学習は導入すれば自動的に成果が出る万能な手法ではありません。どの業務で、どの判断を支援したいのかという目的を明確にし、データや運用を含めて検討することが重要です。
まずは自社の課題や業務プロセスを整理し、機械学習が本当に有効な選択肢かを見極めることが第一歩となります。そのうえで、段階的に検証や活用を進めていくことで、機械学習をビジネスの成果につなげやすくなるでしょう。
【お役立ち資料】機械学習・生成AIを「理解」で終わらせないための一冊
機械学習や生成AIは、正しく導入・活用できれば業務効率化や生産性向上につながります。本資料では、生成AIを導入するためのメリットや、企業で導入を進める際に直面しやすい8つの課題とその対策ポイントを整理。初期検討から実務での活用まで、導入をスムーズに進めるための考え方と進め方を分かりやすくまとめています。